So the way that the Builder objects that build these ESM-Datastores work is that they open every file in the directory, and extract various metadata needed for cataloguing it - all the fields you see in the datastore, basically.
For variable_cell_methods, (and all the other variable_xyz fields) , these are extracted by looping over all the variables in the files & extracting their attributes.
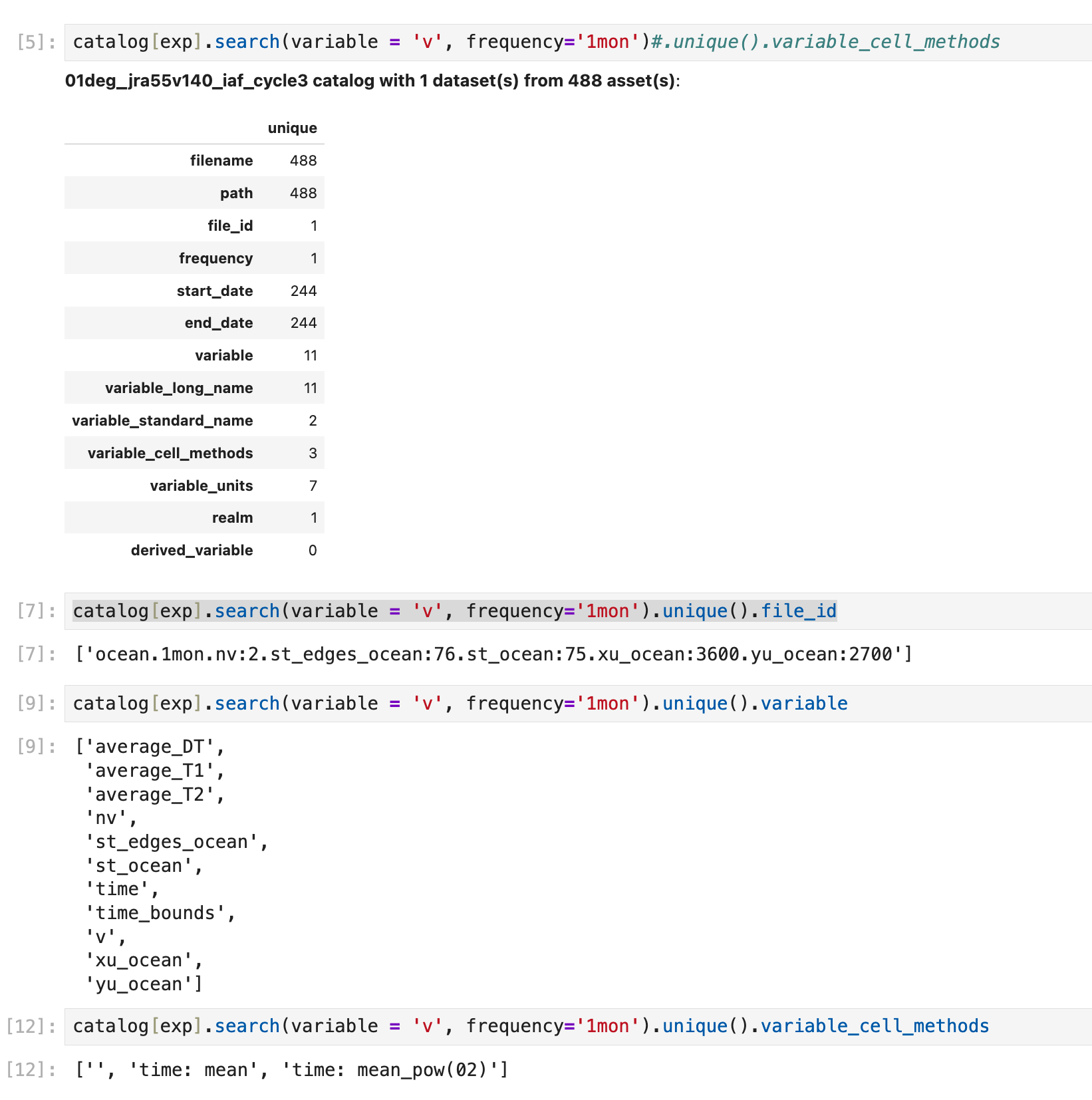
So, for eg. v variable_cell_methods = [ds['v'].attrs.get("cell_methods", "").
The .get("cell_methods","") means that if no cell methods are found for that variable, an empty string will be used as an empty value - which is where that is coming from. Potentially it would be better to just remove it.
I’m not sure I asked exactly what I was trying to, reading it back. The complication is that I don’t think it’s straightforward to disambiguate based on variable cell methods - imagine the following scenario:
- Imagine we have three files: the first with
v_mean and v_max, the second with v_max and the third with v_mean (this is going to seem a bit contrived, but stay with me).
- All are on the same grid.
- File 1 will have
variable_cell_methods = ['time: mean','time: max'] ; file 2 variable_cell_methods = ['time: max']; file 3 variable_cell_methods = ['time': mean'].
In this scenario, if we try to disambiguate on variable_cell_methods - that is, split up what we consider a dataset based on that - we will wind up telling intake-esm that none of these files can be combined.
I think we would actually want to be able to combine 1 & 2 or 1 & 3, but not 2 & 3.
Arguably this is the safest way of handling things, but it might also a become a bit inconvenient. I was looking through the full catalog & I found a bunch of datasets where it looks like cell methods only on differ things like nv and rho2. For eg. an Eulerian velocity field, we probably wouldn’t want to differentiate into datasets based on whether one file contains a maximum on density surfaces and another doesn’t?
I thiiink the behaviour that we want is something like:
- If a specific variable has been searched for (ie.
esm_datastore.search(variable = 'xyz').to_dask()), then make sure that for each file that we open in that dataset, we ensure all the variables in the dataset have compatible cell methods?
Intake-ESM already has some code that handles this sort of stuff & we could extend that - if you search for variable x it will know to only put x (and necessary coordinate variables) into the dataset it returns from to_dask.