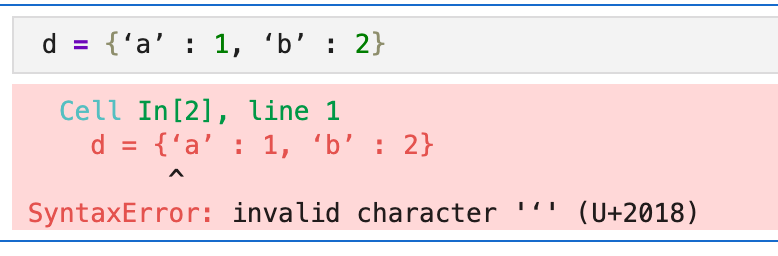
Finally reporting this as I’ve noticed this issue in 26.02 and it now appears in 26.03:
Loading ht variable in later conda envs (e.g. 26.03, 26.02..) gives error although the same script works fins in 26.01..
var=‘ht’
ht = catalog[iaf_cycle4].search(
variable=var,
).to_dask(
threaded=False,
xarray_open_kwargs = {
“decode_timedelta” : True}
)
ValueError Traceback (most recent call last)
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/source.py:323, in ESMDataSource._open_dataset(self)
322 else:
--> 323 raise exc
325 self._ds.attrs[OPTIONS['dataset_key']] = self.key
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/source.py:308, in ESMDataSource._open_dataset(self)
307 try:
--> 308 self._ds = xr.combine_by_coords(
309 datasets, **self.xarray_combine_by_coords_kwargs
310 )
311 except ValueError as exc:
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/xarray/structure/combine.py:1125, in combine_by_coords(data_objects, compat, data_vars, coords, fill_value, join, combine_attrs)
1123 # Perform the multidimensional combine on each group of data variables
1124 # before merging back together
-> 1125 concatenated_grouped_by_data_vars = tuple(
1126 _combine_single_variable_hypercube(
1127 tuple(datasets_with_same_vars),
1128 fill_value=fill_value,
1129 data_vars=data_vars,
1130 coords=coords,
1131 compat=compat,
1132 join=join,
1133 combine_attrs=combine_attrs,
1134 )
1135 for vars, datasets_with_same_vars in grouped_by_vars
1136 )
1138 return merge(
1139 concatenated_grouped_by_data_vars,
1140 compat=compat,
(...) 1143 combine_attrs=combine_attrs,
1144 )
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/xarray/structure/combine.py:1126, in <genexpr>(.0)
1123 # Perform the multidimensional combine on each group of data variables
1124 # before merging back together
1125 concatenated_grouped_by_data_vars = tuple(
-> 1126 _combine_single_variable_hypercube(
1127 tuple(datasets_with_same_vars),
1128 fill_value=fill_value,
1129 data_vars=data_vars,
1130 coords=coords,
1131 compat=compat,
1132 join=join,
1133 combine_attrs=combine_attrs,
1134 )
1135 for vars, datasets_with_same_vars in grouped_by_vars
1136 )
1138 return merge(
1139 concatenated_grouped_by_data_vars,
1140 compat=compat,
(...) 1143 combine_attrs=combine_attrs,
1144 )
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/xarray/structure/combine.py:764, in _combine_single_variable_hypercube(datasets, fill_value, data_vars, coords, compat, join, combine_attrs)
759 raise ValueError(
760 "At least one Dataset is required to resolve variable names "
761 "for combined hypercube."
762 )
--> 764 combined_ids, concat_dims = _infer_concat_order_from_coords(list(datasets))
766 if fill_value is None:
767 # check that datasets form complete hypercube
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/xarray/structure/combine.py:174, in _infer_concat_order_from_coords(datasets)
173 else:
--> 174 raise ValueError(
175 "Could not find any dimension coordinates to use to "
176 "order the Dataset objects for concatenation"
177 )
179 combined_ids = dict(zip(tile_ids, datasets, strict=True))
ValueError: Could not find any dimension coordinates to use to order the Dataset objects for concatenation
The above exception was the direct cause of the following exception:
ESMDataSourceError Traceback (most recent call last)
Cell In[32], line 4
1 var='ht'
2 ht = catalog[iaf_cycle4].search(
3 variable=var,
----> 4 ).to_dask(
5 threaded=False,
6 xarray_open_kwargs = {
7 "decode_timedelta" : True}
8 )
9 ht = ht['ht']
10 ht = ht.sel(yt_ocean = lat_slice).sel(xt_ocean=lon_slice)
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/core.py:888, in esm_datastore.to_dask(self, **kwargs)
884 if len(self) != 1: # quick check to fail more quickly if there are many results
885 raise ValueError(
886 f'Expected exactly one dataset. Received {len(self)} datasets. Please refine your search or use `.to_dataset_dict()`.'
887 )
--> 888 res = self.to_dataset_dict(**{**kwargs, 'progressbar': False})
889 if len(res) != 1: # extra check in case kwargs did modify something
890 raise ValueError(
891 f'Expected exactly one dataset. Received {len(self)} datasets. Please refine your search or use `.to_dataset_dict()`.'
892 )
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/pydantic/_internal/_validate_call.py:39, in update_wrapper_attributes.<locals>.wrapper_function(*args, **kwargs)
37 @functools.wraps(wrapped)
38 def wrapper_function(*args, **kwargs):
---> 39 return wrapper(*args, **kwargs)
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/pydantic/_internal/_validate_call.py:136, in ValidateCallWrapper.__call__(self, *args, **kwargs)
133 if not self.__pydantic_complete__:
134 self._create_validators()
--> 136 res = self.__pydantic_validator__.validate_python(pydantic_core.ArgsKwargs(args, kwargs))
137 if self.__return_pydantic_validator__:
138 return self.__return_pydantic_validator__(res)
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/core.py:760, in esm_datastore.to_dataset_dict(self, xarray_open_kwargs, xarray_combine_by_coords_kwargs, preprocess, storage_options, progressbar, aggregate, skip_on_error, threaded, **kwargs)
758 except Exception as exc:
759 if not skip_on_error:
--> 760 raise exc
761 self.datasets = self._create_derived_variables(datasets, skip_on_error)
762 return self.datasets
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/core.py:756, in esm_datastore.to_dataset_dict(self, xarray_open_kwargs, xarray_combine_by_coords_kwargs, preprocess, storage_options, progressbar, aggregate, skip_on_error, threaded, **kwargs)
754 for task in gen:
755 try:
--> 756 key, ds = task.result()
757 datasets[key] = ds
758 except Exception as exc:
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/concurrent/futures/_base.py:449, in Future.result(self, timeout)
447 raise CancelledError()
448 elif self._state == FINISHED:
--> 449 return self.__get_result()
451 self._condition.wait(timeout)
453 if self._state in [CANCELLED, CANCELLED_AND_NOTIFIED]:
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/concurrent/futures/_base.py:401, in Future.__get_result(self)
399 if self._exception:
400 try:
--> 401 raise self._exception
402 finally:
403 # Break a reference cycle with the exception in self._exception
404 self = None
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/concurrent/futures/thread.py:59, in _WorkItem.run(self)
56 return
58 try:
---> 59 result = self.fn(*self.args, **self.kwargs)
60 except BaseException as exc:
61 self.future.set_exception(exc)
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/core.py:907, in _load_source(key, source)
906 def _load_source(key, source):
--> 907 return key, source.to_dask()
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/source.py:336, in ESMDataSource.to_dask(self)
334 def to_dask(self):
335 """Return xarray object (which will have chunks)"""
--> 336 self._load_metadata()
337 return self._ds
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake/source/base.py:84, in DataSourceBase._load_metadata(self)
82 """load metadata only if needed"""
83 if self._schema is None:
---> 84 self._schema = self._get_schema()
85 self.dtype = self._schema.dtype
86 self.shape = self._schema.shape
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/source.py:253, in ESMDataSource._get_schema(self)
251 def _get_schema(self) -> Schema:
252 if self._ds is None:
--> 253 self._open_dataset()
254 metadata: dict[str, typing.Any] = {'dims': {}, 'data_vars': {}, 'coords': ()}
255 self._schema = Schema(
256 datashape=None,
257 dtype=None,
(...) 260 extra_metadata=metadata,
261 )
File /g/data/xp65/public/apps/med_conda/envs/analysis3-26.03/lib/python3.12/site-packages/intake_esm/source.py:328, in ESMDataSource._open_dataset(self)
325 self._ds.attrs[OPTIONS['dataset_key']] = self.key
327 except Exception as exc:
--> 328 raise ESMDataSourceError(
329 f"""Failed to load dataset with key='{self.key}'
330 You can use `cat['{self.key}'].df` to inspect the assets/files for this key.
331 """
332 ) from exc
ESMDataSourceError: Failed to load dataset with key='ocean.fx.xt_ocean:3600.yt_ocean:2700.point'
You can use `cat['ocean.fx.xt_ocean:3600.yt_ocean:2700.point'].df` to inspect the assets/files for this key.