Hi earth system users. I’ve run a year of the u-cy339 suite in ACCESS-CM2 following these instructions. I think the job completed successfully. I.e. this is the job.out file:
However, the output files seem to be uncollated in the work directory (e.g. ocean files are here: /scratch/jk72/hd4873/cylc-run/u-cy339/work/09500101/coupled/OCN_RUNDIR/HISTORY). I have no archive directory on scratch, like the instructions suggest I should have.
Should the output files automatically be collated and moved into an archive directory, or do I need to create the archive directory myself and run a post-processing script for this step?
If you followed the linked instructions (you did not change any archive paths) it is strange that you don’t have the archive directory on scratch.
I don’t have access to jk72 yet (I requested it) so I cannot check it myself, but I suspect some tasks did not complete successfully.
Can you please check the coupled/NN/job.err log file to see if there were any errors in the coupled task?
If that shows no error, I might have to wait for the jk72 approval to have a better look of what happened, because I need to check if there are any tasks that ran after coupled and failed (for example I see a filemove task in u-cy339 that might be the one responsible of the move from the work directory to the archive, but to be sure I need to check the files).
Thanks @atteggiani for following this up. Yep, I followed the instructions quite closely. The only thing I changed was the cycling frequency and run length (to 1 year each, if I recall).
I can see several warnings in the job.err file but no errors.
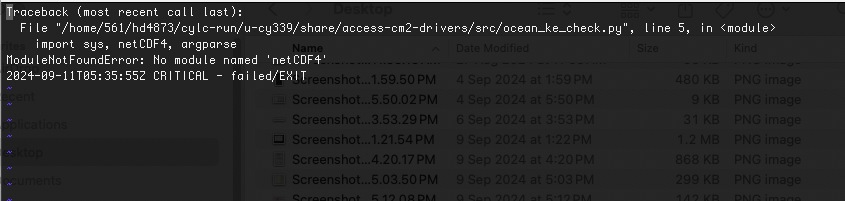
To find the nature of the problem you’ll have to check the /scratch/jk72/hd4873/cylc-run/u-cy339/log/job/09500101/ocean_ke_check/NN/job.err file:
Traceback (most recent call last):
File "/home/561/hd4873/cylc-run/u-cy339/share/access-cm2-drivers/src/ocean_ke_check.py", line 5, in <module>
import sys, netCDF4, argparse
ModuleNotFoundError: No module named 'netCDF4'
2024-08-26T09:06:03Z CRITICAL - failed/EXIT
So it seems that the ocean_ke_check job failed because it cannot find the netCDF4 module in the environment.
This is weird because the runtime suiterc file (/scratch/jk72/hd4873/cylc-run/u-cy339/log/suiterc/20240826T043259Z-run.rc) at line 1287-1291 loads the hh5conda/analysis3 module (that has the netCDF4 dependency) as a pre-script to the ocean_ke_check task:
Thanks for looking into this @atteggiani! Really appreciate it. Hopefully @MartinDix has some further insights (no problem if it’s after the NRI workshop).
Indeed it runs exactly in the persistent session. However, the persistent session should have access to any project the user that starts it has access to (if I remember correctly).
Might be worth to double check though, I’ll run some tests.
I just tried ssh-ing to the persistent session and I can see all projects as if I was on a Gadi login node.
So I don’t think that’s the problem with this issue.
My run completed without issues.
The ocean_ke_check task completes fine.
Can you please try running the suite again and see if the problem persists?
To avoid weird issues please do the following:
Clean suite data
Delete the suite
Checkout a copy of the suite
Change run length to 1 month
Run the suite
All of the above can be executed with the following commands:
cd ~/roses/u-cy339
rose suite-clean -y
cd && rm -rf u-cy339
rosie checkout u-cy339
sed -i "s|\(^RUNLEN=\).*|\1'P1M'|" ~/roses/u-cy339/rose-suite.conf
rose suite-run -C ~/roses/u-cy339
In your failed attempt, did you run your suite from inside a persistent-session?
In general there should never be the need to ssh to a persistent-session (very few exceptions apply).
All the commands above can be run from a Gadi login node (or ARE).
The only important things are:
before loading the cylc7 module (not included in the commands above but needed as a prerequisite to run rose/cylc suites), the file ~/.persistent-sessions/cylc-session exists and has the following line:
Before running the suite, a persistent session named <persistent-session-name> must be running.
If you set up your persistent sessions already, there shouldn’t be the need to change anything.
Just check whether the persistent-session is still running: persisten-session list.
If it is not running, start it with persistent-session start <persistent-session-name>
Okay, it’s running now. No, I don’t think I ran the previous one from inside a persistent session. Hopefully it was just some strange one-of last time. I’ll post once it’s finished.
I ran a full year.
I am not entirely sure because the run stopped because of a server error, so I had to restart it from when it stopped.
I would say in total it took something like 12h.